EECS110 Course
Project Option 2, Spring 2018
Text Clouds
This project offers you an opportunity to use Python to
develop a fun and useful web application.
A text cloud is a collection of the most-commonly
used words within some body of text, usually with attention paid to avoid
extremely common words (e.g., the)
and to unify different forms of a single word (e.g., aliens and alien are the same). Text clouds
allow us to obtain a quick sense of the topic of a website by visualizing the
most frequently occurring words on that website where the words are displayed
with size proportional to the frequency. For example, here is how a text cloud
might look like for Harry Potter and the Sorcerer's Stone:

Although the Harry Potter books are under
copyright and thus aren't available online, you can find many interesting older
books at Project Gutenberg. Here is a
text cloud for Mark Twain's The Adventures of Tom
Sawyer:
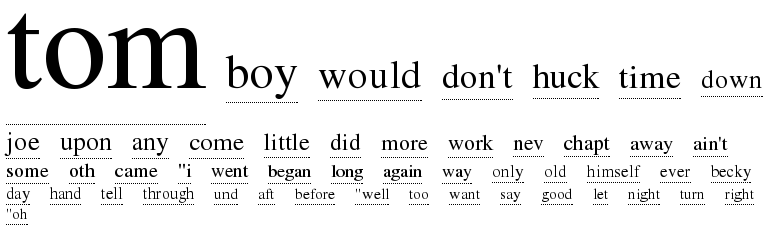
This
site seems to be one of the first to distinguish text clouds from the more
common tag cloud. The
kinds of text cloud this project uses are what Wikipedia calls a data clouds.
Text clouds, in essence, are a word-by-word summary of
the contents of an article, book, or other work. Though certainly the structure
of the document is lost, the relative frequency of particular words may be
telling. Consider for example, the beautiful example of the text cloud for all presidential
state-of-the-union speeches in American history.
A
Few Words on Web Pages, HTML, and URLs
Web pages are written in a language called HTML which
stands for Hyper Text Markup Language. HTML provides instructions that tell
your browser how to format the contents of the web page. If you use your web
browser to look at a web page, you can view the HTML that produced that page
(for example in Firefox, select the "View" menu and then the
"Page Source" option). If you haven't looked at HTML before, take a
few minutes to do so. Don't worry if you don't understand the HTML commands,
but it's instructive just to see how the text and formatting commands appear in
HTML.
You will notice that in addition to text and some other
items in an HTML document there are often some hyperlinks. These are just the
addresses of other web pages. In a HTML document, those hyperlinks are
specified using addresses called URLs (Universal Resource Locaters). For
example, the HTML code
<A HREF="http://www.northwestern.edu/>Northwestern
University website</A>
tells the browser to display the words Northwestern University
website (generally
in a special color, such as blue) and when the user clicks on these words, the
browser should go to the web page at the location given by the URL http://www.northwestern.edu.
This project comprises two parts. The first part is the
milestone is due on due on Sunday, 06/03 at 11:59 PM.
For the milestone, you will write the core functionality of the text clouds
program but without some of the advanced features that you will add for the
final version.
The milestone program will run from the IDLE
environment. It will ask the user for a URL and will then compute the word
frequencies on the web page at that URL address. Finally, it will print the
most frequently occurring words on the screen along with the number of
occurrences of each word. You will not run this program through a web browser
at this point. That comes later!
In the final version of the project, due on Sunday, 06/10 at 11:59 PM, you will add several
additional features. First, when the user enters a URL, your program will not
only examine the words on that website, but it will also explore all of the
URLs that are linked from that website to explore the contents of those linked
page. These linked pages may, in turn, have their own URL links and your
program will explore those as well, etc. This process of "fanning
out" from an initial website is called "web crawling". Your
program will be a text cloud web crawler! In addition, your program will run
from your own web page (details below) and will display the results on your web
browser. Once you have this working, your friends will be able to go to your
website to use your text cloud web crawler.
Quick Notes on Design, Implementation,
and Test
- Design your
code carefully. It is highly recommended that you do this on paper first.
Make sure that your functions and classes encapsulate small logical
components of your larger program.
- Please be sure
that you provide a docstring for every function and method that
you write.
- Where your
code is at all complex, please provide some comments in the code to
explain what's happening.
- Use good and
descriptive variable names.
- Avoid global
variables except where they are absolutely necessary (and that's not very
often!).
- Avoid magic
values!
- Test each
function out after you have written it.
- Test your
entire program thoroughly.
Part
1: The Basic Program for the Milestone
This part is due on Sunday,
06/03
at 11:59 PM.
The basic program runs from IDLE and does the
following:
- It begins by
asking the user to enter a URL (e.g.
http://www.northwestern.edu), complete with thehttp://prefix. Don't forget that prefix when entering a URL. - It then goes
to that website and gets the contents of the website as a string.
- Next, it goes
through that string and separates out the individual words into a list.
- The list of words
is then "cleaned" by removing frequently occurring uninteresting
words (e.g. "a", "the", "I", etc.) and
removing punctuation. The best way to do this is to maintain a list of
words called a "stop list" and remove all words from your text
that occur in that list.
- The remaining
set of words is "stemmed" so that words such as "jog",
"jogs", "jogging", "jogger",
"jogged", etc. are all just transformed to "jog". You
will need to think about how to do this effectively. It's impossible to do
it perfectly, but for this milestone just try to do a reasonable job.
- The words are
then counted to determine their frequency.
- A string is
returned that contains the words sorted from most frequently to least
frequently occurring, with the number of occurrences following each word
(in parentheses). In order to avoid displaying too many words, there
should be a global variable in your program called
MAXWORDS. This global variable dictates the number of words that are returned. For example ifMAXWORDSis set to 50, only the 50 most frequently occurring words will be returned. - That string of
the
MAXWORDSmost frequently occurring strings is printed on the screen. The words appear in order from most frequent to least frequent, with each word followed by the number of times it occurs (in parentheses). This is a simple version of a text cloud!
For the milestone, you may have very simple and
far-from-perfect "cleaning" and "stemming". You should have
functions in place for those tasks and some rudimentary "cleaning"
and "stemming" should take place, but you can refine this
substantially in the final version of your program.
For example,
here is what your program might look like when your program is run on the web
page http://networks.cs.northwestern.edu/EECS110-s18/projects/project2/page2.htm
Enter a URL:
http://networks.cs.northwestern.edu/EECS110-s18/projects/project2/page2.htm
Here is the text cloud for your web page:
spam (8)
page (2)
love (1)
Your output might not look exactly like this. In
particular, you may have other strings in your output or slightly different
counts, depending on your stemming rules. Notice here that the word
"I" appeared on that web page but was not included in the text cloud
because it got "cleaned" out as the program dropped frequently
occurring words in its stop list.
What
You'll Need for the Basic Program
If by any chance you are NOT using Python Version 3.5, download the file hmc_urllib by right-clicking here: hmc_urllib.py and
saving that file in the directory where you are doing your programming.
FOR PYTHON VERSION 3.5, download the file hmc_urllib_new by right-clicking here: hmc_urllib_new.py and
saving that file in the directory where you are doing your programming. If you
download the other file , the program wont work so make sure to download the
hmc_urllib_new.py
Make sure that this file is in the same directory or
folder where you are developing your project. Now, you will need the following
line at the top of your program:
from hmc_urllib import getHTML (FOR PYTHON VERSION 3.5...you
would write: from hmc_urllib_new import getHTML)
This line gives you access to a Python library for
dealing with HTML. It provides the function getHTML; you can use help(getHTML) to see its documentation. It simply
takes a string as input, where that string is a URL. A URL always begins with http:// as in http://www.northwestern.edu. The function returns a
2-tuple that contains the text of the web page and the URLs that appear on that
web page. The text of the web page is returned in all lower case letters. This
is done in order to avoid counting uppercase and lowercase spellings as
different words. Please use this function as-is.
Note that this library will only return pages at
Northwestern University (anything at northwestern.edu, etc). We put this
restriction on the code because people who run web sites might get annoyed if
they suddenly had dozens of Northwestern programs disrespectfully crawling
their website (there are restrictions about how programs can
"respectfully" crawl web sites which we are not going to get into
here. Furthermore, bugs in a program almost always render them
"disrespectful" :)).
For this milestone, you can ignore the URLs that are
returned. You will use those in an interesting way on the final version of the
project.
There are two other ingredients that will be useful. First,
you will need to manipulate strings in all sorts of ways. To that end, use
Python's many built-in string methods. While we've seen some string handling
methods in class, the string
sections in the Python
library reference is a great place to learn about Python's string handling
methods. These resources will help with parsing, cleaning the input, and even
stemming the words.
Second, you will need to sort. Python has a built-in
method for sorting lists. If you have a list called foo then the command foo.sort() will sort that list in increasing order. It
can sort lists of strings, lists of numbers, and even lists of lists and lists
tuples! When sorting a list of lists (or tuples), it sorts first according to
the first element in each list or tuple, breaking ties by looking at the next
element, etc. Experiment with this!
Be sure to test each function as you write it. Writing
all of the functions and only then testing the whole program is a recipe for
headaches.
You may want to test your program on some very small
web pages. Here are three web pages that you may want to use to test your
program:
http://networks.cs.northwestern.edu/EECS110-s18/projects/project2/page1.htm
http://networks.cs.northwestern.edu/EECS110-s18/projects/project2/page2.htm
http://networks.cs.northwestern.edu/EECS110-s18/projects/project2/page3.htm
What To Submit for the first Milestone
By Sunday, 06/03 at 11:59 PM
you should submit your first milestone. This includes:
- A file called
pr2_milestone.txtthat tells us which project you are submitting and your name (and your partner's name if it is a joint submission). - Your program
in a file called
pr2_milestone.py. - Any additional
files that you wrote and your program uses (other than
hmc_urllib.py).? For example, pr2_milestone_sup1.py, pr2_milestone_sup2.py, etc. - Submit your
solutions at Canvas
The
Final Project
The final project adds the following features to the
basic program and is due on Sunday, 06/10 at 11:59 PM.
When a user enters a URL into your program, the program
grabs the text from that URL as before. However, the program then looks at all
of the web pages referred to by URLs on that web page. Recall that the function getHTML that we have provided above returns this
list of URLs. This process of automatically going from one web page to other
web pages that are linked from that page is called "web crawling".
Web crawling can be very slow if the web page where you
begin your search has links to other pages that have links to other pages, etc.
Therefore, your program should have a global variable called DEPTH that enforces that your program never
crawls more than that number of links away from the starting web page. For
example, if DEPTH is
set to 0, then only the starting page is searched. If DEPTH is set to 1 then only the starting page and
pages linked from that page are searched, etc. For debugging purposes, set DEPTH equal to 0 initially and then increase this
number later.
So, your program will now begin at the start URL
provided by the user and crawl to all web pages reachable within DEPTH "hops" of that web page. In the
end, it will display a single text cloud that aggregates all of the words found
during that "crawl".
You will need to be careful here. Imagine that you
start at a URL for a web page. Let's call that page X. Imagine that X has links to pages Y and Z. If the DEPTH is one or more, your program will look at
pages Y and Z. Imagine now that Y has links to A and B but also to X and Z. You need to make sure that Y does not send us back to X since we have already been there and presumably
we've already counted the words on that page. Counting them again would be a
mistake! Similarly, we need to make sure that Z is
only visited once. If we're not careful, X will visit Z and also Y will visit Z, resulting in double-counting of the words
on page Z.
How do we handle this? You may wish to use imperative
or recursive constructs. That's up to you. In order to avoid visiting a page
twice, you may want to keep a list of the URLs that have already been visited.
Then, before exploring a URL, check to see if it is in the list of already
visited URLs. If so, don't visit it again. Similarly, when a URL is explored
for the first time, we'll need to place it on that list!
You can test your code using the same test pages listed
above. First test from page1.html with DEPTH set to 0. This will give you a text cloud
only for the words on that page. Now try again with DEPTH set to 1. This will give you a text cloud
for the words on page1.html and page2.html (because there is a link from page1.html to page2.html). How try again with DEPTH set to 2.
Your final submission should have the following
features:
- The web
crawling feature should work. Remember to have a global
DEPTHvariable that controls the depth of web crawling. Please have this set to 2 for your final submission, although we'll change it's value when we test your code. - Improve your
word "cleaning" and "stemming" so that it works well.
It's impossible to be perfect, but you should have on the order of ten or more
rules for stemming implemented that result in a reasonably good job. In
particular:
- Your cleaner
should remove numbers and punctuation, including apostrophes.
- Your stemmer
should stem plural words to singular words (as well as you can) and do a
good job of removing "ing", "er", "ed", and
other common endings.
- Finally, you
should have your program work from a website. More on how to do that
below.
Making Your Text Clouds Web-Based
The last part of this project is to make your text cloud
program run on its own website. In other words, the user will now enter URLs on
a web page rather than from IDLE. The resulting text cloud will be displayed on
a web page as well. For example, you can take a look at a very basic example at
http://blue.cs.northwestern.edu/~emirhan/
Here's what you'll need to do to make this work:
Name your python program textcloud.py.
Remove all
print statements from textcloud.py. This is important for the
correct functionality of your program on the web.
Add a function to your program called mtcURL that takes as input a URL
(a string) and returns (not
prints!) a string of all
of the words that you want to display in your textcloud. The code that we have
provided will call mtcURL exactly once, so it is
imperative that mtcURL return the totality of the
words accumulated during the web crawl. The string should be returned in the
following format: For each of the words in your text cloud (recall that there
are at most MAXWORDS
of them and they appear in sorted order from most frequent to least frequent)
there is a string of the form:
<abbr title = COUNT style =
"font-size:NUMBER%">WORD</abbr>
where COUNT is the number of
occurrences of the WORD and NUMBER is the relative size of the font used to
display the WORD. You can choose the NUMBER to be anything that you like, but it should
be proportional to the number of occurrences (COUNT) of
the WORD. You may want to experiment
with these sizes to see what looks good to you.
For example, for the Harry Potter text cloud, the first
few lines might look like:
<abbr title =1267
style="font-size:800%">harry</abbr>
<abbr title =417
style="font-size:263%">ron</abbr>
<abbr title =335
style="font-size:211%">hagrid</abbr>
<abbr title =254
style="font-size:160%">hermione</abbr>
<abbr title =174
style="font-size:109%">down</abbr>
Notice that this tells us that the word
"Harry" appears 1267 times in the file and its font size is 800% of
the normal font size. The word "Ron" appeared 417 times and its font
size is 263% of the normal font size. The numbers 800 and 263 are not
important. What is important is that the ratio of these percentages (in this
case 800/263) is equal to the ratio of the word counts (in this case 1267/417).
This funny format is HTML! It will tell a web browser
the font size for each of these words. The nbsp's are spacers that put a bit of
separation between the words on the web page. Test your program to make sure
that it produces output in exactly
this format. Any mistake in the format will cause an error when you move on to
the next step.
IMPORTANT NOTE: Please thoroughly test your mtcURL
function in IDLE before moving on to the final steps below.
You can test it by giving it a url string (for simple test web pages such as
those that we've provided for you) and seeing if it correct output in the
format described above. Once you've done this testing, you can be quite sure
that you are almost done. However, failing to test this code now may result in
severe headaches on the very last part described below.
In order to be able to setup your own web pages you
will need a remote account on the Blue machine (blue.cs.northwestern.edu). In
order to get one you will e-mail emirhan@u.northwestern.edu
requesting a username and password.
On Windows or Mac machines, you may want to download SSH Secure Shell,
a program that allows you to move files between your machine and other machines
(e.g. the Blue machine). You can use this program to connect and login with
your provided username and password to blue.cs.northwestern.edu and you will see your remote files
through SSH. Note that, SSH is build-in protocol in Unix family laptops (e.g. Macs), but
you may need to enable it from your terminal. PuTTY is another secure protocol to connect to remote
servers and widely used for Windows machines. There are many more instructions online for both of them on how to install and run from your local machine (your laptop).
On the Blue machine, you have a home directory. This
is where you're logged in when you use Blue.
Within that directory, first create a folder named public_html. Any documents you put - with the correct
permissions - in the public_html folder will be publicly
viewable. There are four files needed to set up a website that uses Python.
They are
1.
index.html
2.
index.py
3.
Your textcloud.py file
4.
The hmc_urllib.py file
The instructions below explain how to download these
files, place them in the right directory, and set their permissions
appropriately. These
files must be installed on the Blue web server. To minimize
headaches, you may wish to do this during the scheduled lab time so that the
lab instructors and TAs can help you. However, you can also do it on your own,
even from your own computer.
Now that you are logged on to the Blue machine (by
connecting remotely as discussed above) here's what you will do:
Get the index.html page. First open this this page. Then right-clicking or
control-clicking on the screen and click "view page source".
You will see the html text format of the page. Then copy all text and save it in a file as index.html onto your machine. Then, move
that file into your public_html directory on Blue. If you wish, you can open
the file for editing (for example, with IDLE or any other text editor).
Next, copy the text below into a file called index.py. Then, save that file as index.py onto your machine. Then, move that file
into your public_html directory.
#!/usr/local/bin/python3
import cgi
import cgitb; cgitb.enable()
import textcloud
def htmlFormat( body = 'No text supplied', title = 'EECS 110 project
page' ):
""" takes the title and body
of your webpage (as a string)
and adds the html formatting, returning the
resulting
string. If you want to use some features, you
may have to
change this function (or not use it at
all...)
"""
startString = """\
Content-Type: text/html;
<html>
<head>
<title>
"""
afterTitle = """\
</title>
</head>
<body>
"""
afterBody = """\
</body>
</html>
"""
return startString + title + afterTitle +
body + afterBody
form = cgi.FieldStorage()
if 'inputurl' in form and len(form['inputurl'].value.strip())
> 0:
url = form['inputurl'].value
url.strip()
textcloudbody = textcloud.mtcURL( url )
else:
text = 'I don\'t know what\'s going on.'
textcloudbody = text
originalURL = "<h3><a
href=\"./index.html\">Back to text-cloud
creation</a></h3>\n"
htmlout = htmlFormat(textcloudbody)
print(htmlout)? # this renders the
page
Next, copy your textcloud.py and the supplied hmc_urllib.py file into your public_html directory.
Once that index.html file is in your
public_html folder, you need to set permissions to make it world-readable. Open
a terminal window. Type cd ~/public_html to
put yourself in the public_html directory. Then, type chmod ugo+rx * to change the access permissions of a file
so that outside users can use your files. (You can learn much, much
more about permissions by typing man
chmod)
Once everything is in place, make sure that you can see
your base page (which is the index.html one). It will be at
http://blue.cs.northwestern.edu/~yourusername
Go to that URL with a web browser and your program will
be running from the web! Congratulations!
You are welcome to add customizations and
embellishments to your project. For example, you might wish to add
colors to the fonts that are used to display the text clouds. The colors might
use to represent some additional information. Please explain any such added
features in the textcloud.txt file that you submit along
with your python program.
What to Submit for your Final Project
Here's what you should submit for your final project.
- A text file
named
textcloud.txtthat tells us your name, the name of your partner (if any). Please also explain and describe any additional features that you have added. - Your program
in a file called
textcloud.py. - Any additional
files python that you wrote and your program uses. For example, pr2_final_sup1.py,
pr2_final_sup2.py, etc.
Submit your solutions at Canvas
.